To see posts by date, check out the archives
Over the past six months, I’ve tracked my money with hledger—a plain text
double-entry accounting system written in Haskell. It’s been
surprisingly painless.
My previous attempts to pick up real accounting tools floundered. Hosted tools are privacy nightmares, and my stint with GnuCash didn’t last.
But after stumbling on Dmitry Astapov’s “Full-fledged
hledger” wiki1, it
clicked—eventually consistent accounting. Instead of
modeling your money all at once, take it one hacking session at a
time.
It should be easy to work towards eventual consistency. […] I should be able to [add financial records] bit by little bit, leaving things half-done, and picking them up later with little (mental) effort.
– Dmitry Astapov, Full-Fledged Hledger
Principles of my system
I’ve cobbled together a system based on these principles:
- Avoid manual entry – Avoid typing in each transaction. Instead, rely on CSVs from the bank.
- CSVs as truth – CSVs are the only things that matter. Everything else can be blown away and rebuilt anytime.
- Embrace version control – Keep everything under version control in Git for easy comparison and safe experimentation.
Learn hledger in five minutes
hledger concepts are heady, but its use is simple. I
divide the core concepts into two categories:
- Stuff
hledgercares about:- Transactions – how
hledgermoves money between accounts. - Journal files – files full of transactions
- Transactions – how
- Stuff I care about:
- Rules files – how I set up accounts, import CSVs, and move money between accounts.
- Reports – help me see where my money is going and if I messed up my rules.
Transactions move money between accounts:
2024-01-01 Payday
income:work $-100.00
assets:checking $100.00This transaction shows that on Jan 1, 2024, money moved from
income:work into assets:checking—Payday.
The sum of each transaction should be $0. Money comes from somewhere, and the same amount goes somewhere else—double-entry accounting. This is powerful technology—it makes mistakes impossible to ignore.
Journal files are text files containing one or more transactions:
2024-01-01 Payday
income:work $-100.00
assets:checking $100.00
2024-01-02 QUANSHENG UVK5
assets:checking $-29.34
expenses:fun:radio $29.34Rules files transform CSVs into journal files via regex matching.
Here’s a CSV from my bank:
Transaction Date,Description,Category,Type,Amount,Memo
09/01/2024,DEPOSIT Paycheck,Payment,Payment,1000.00,
09/04/2024,PizzaPals Pizza,Food & Drink,Sale,-42.31,
09/03/2024,Amazon.com*XXXXXXXXY,Shopping,Sale,-35.56,
09/03/2024,OBSIDIAN.MD,Shopping,Sale,-10.00,
09/02/2024,Amazon web services,Personal,Sale,-17.89,And here’s a checking.rules to transform that CSV into a
journal file so I can use it with hledger:
# checking.rules
# --------------
# Map CSV fields → hledger fields[0]
fields date,description,category,type,amount,memo,_
# `account1`: the account for the whole CSV.[1]
account1 assets:checking
account2 expenses:unknown
skip 1
date-format %m/%d/%Y
currency $
if %type Payment
account2 income:unknown
if %category Food & Drink
account2 expenses:food:dining
# [0]: <https://hledger.org/hledger.html#field-names>
# [1]: <https://hledger.org/hledger.html#account-field>With these two files (checking.rules and
2024-09_checking.csv), I can make the CSV into a
journal:
$ > 2024-09_checking.journal \
hledger print \
--rules-file checking.rules \
-f 2024-09_checking.csv
$ head 2024-09_checking.journal
2024-09-01 DEPOSIT Paycheck
assets:checking $1000.00
income:unknown $-1000.00
2024-09-02 Amazon web services
assets:checking $-17.89
expenses:unknown $17.89Reports are interesting ways to view transactions between accounts.
There are registers, balance sheets, and income statements:
$ hledger incomestatement \
--depth=2 \
--file=2024-09_bank.journal
Revenues:
$1000.00 income:unknown
-----------------------
$1000.00
Expenses:
$42.31 expenses:food
$63.45 expenses:unknown
-----------------------
$105.76
-----------------------
Net: $894.24At the beginning of September, I spent $105.76 and made
$1000, leaving me with $894.24.
But a good chunk is going to the default expense account,
expenses:unknown. I can use the
hleger aregister to see what those transactions are:
$ hledger areg expenses:unknown \
--file=2024-09_checking.journal \
-O csv | \
csvcut -c description,change | \
csvlook
| description | change |
| ------------------------ | ------ |
| OBSIDIAN.MD | 10.00 |
| Amazon web services | 17.89 |
| Amazon.com*XXXXXXXXY | 35.56 |
lThen, I can add some more rules to my
checking.rules:
if OBSIDIAN.MD
account2 expenses:personal:subscriptions
if Amazon web services
account2 expenses:personal:web:hosting
if Amazon.com
account2 expenses:personal:shopping:amazonNow, I can reprocess my data to get a better picture of my spending:
$ > 2024-09_bank.journal \
hledger print \
--rules-file bank.rules \
-f 2024-09_bank.csv
$ hledger bal expenses \
--depth=3 \
--percent \
-f 2024-09_checking2.journal
30.0 % expenses:food:dining
33.6 % expenses:personal:shopping
9.5 % expenses:personal:subscriptions
16.9 % expenses:personal:web
--------------------
100.0 %For the Amazon.com purchase, I lumped it into the
expenses:personal:shopping account. But I could dig
deeper—download my
order history from Amazon and categorize that spending.
This is the power of working bit-by-bit—the data guides you to the next, deeper rabbit hole.
Goals and non-goals
Why am I doing this? For years, I maintained a monthly spreadsheet of account balances. I had a balance sheet. But I still had questions.
Before diving into accounting software, these were my goals:
- Granular understanding of my spending – The big one. This is where my monthly spreadsheet fell short. I knew I had money in the bank—I kept my monthly balance sheet. I budgeted up-front the % of my income I was saving. But I had no idea where my other money was going.
- Data privacy – I’m unwilling to hand the keys to my accounts to YNAB or Mint.
- Increased value over time – The more time I put in, the more value I want to get out—this is what you get from professional tools built for nerds. While I wished for low-effort setup, I wanted the tool to be able to grow to more uses over time.
Non-goals—these are the parts I never cared about:
- Investment tracking – For now, I left this out of scope. Between monthly balances in my spreadsheet and online investing tools’ ability to drill down, I was fine.2
- Taxes – Folks smarter than me help me understand my yearly taxes.3
- Shared system – I may want to share reports from this system, but no one will have to work in it except me.
- Cash – Cash transactions are unimportant to me. I withdraw money from the ATM sometimes. It evaporates.
hledger can track all these things. My setup is flexible
enough to support them someday. But that’s unimportant to me right
now.
Monthly maintenance
I spend about an hour a month checking in on my money Which frees me to spend time making fancy charts—an activity I perversely enjoy.
Here’s my setup:
$ tree ~/Documents/ledger
.
├── export
│ ├── 2024-balance-sheet.txt
│ └── 2024-income-statement.txt
├── import
│ ├── in
│ │ ├── amazon
│ │ │ └── order-history.csv
│ │ ├── credit
│ │ │ ├── 2024-01-01_2024-02-01.csv
│ │ │ ├── ...
│ │ │ └── 2024-10-01_2024-11-01.csv
│ │ └── debit
│ │ ├── 2024-01-01_2024-02-01.csv
│ │ ├── ...
│ │ └── 2024-10-01_2024-11-01.csv
│ └── journal
│ ├── amazon
│ │ └── order-history.journal
│ ├── credit
│ │ ├── 2024-01-01_2024-02-01.journal
│ │ ├── ...
│ │ └── 2024-10-01_2024-11-01.journal
│ └── debit
│ ├── 2024-01-01_2024-02-01.journal
│ ├── ...
│ └── 2024-10-01_2024-11-01.journal
├── rules
│ ├── amazon
│ │ └── journal.rules
│ ├── credit
│ │ └── journal.rules
│ ├── debit
│ │ └── journal.rules
│ └── common.rules
├── 2024.journal
├── Makefile
└── READMEProcess:
- Import – download a CSV for the month from each
account and plop it into
import/in/<account>/<dates>.csv - Make – run
make - Squint – Look at
git diff; if it looks good,git add . && git commit -m "💸"otherwise reviewhledger aregto see details.
The Makefile generates everything under
import/journal:
- journal files from my CSVs using their corresponding rules.
- reports in the
exportfolder
I include all the journal files in the 2024.journal with
the line: include ./import/journal/*/*.journal
Here’s the Makefile:
SHELL := /bin/bash
RAW_CSV = $(wildcard import/in/**/*.csv)
JOURNALS = $(foreach file,$(RAW_CSV),$(subst /in/,/journal/,$(patsubst %.csv,%.journal,$(file))))
.PHONY: all
all: $(JOURNALS)
hledger is -f 2024.journal > export/2024-income-statement.txt
hledger bs -f 2024.journal > export/2024-balance-sheet.txt
.PHONY clean
clean:
rm -rf import/journal/**/*.journal
import/journal/%.journal: import/in/%.csv
@echo "Processing csv $< to $@"
@echo "---"
@mkdir -p $(shell dirname $@)
@hledger print --rules-file rules/$(shell basename $$(dirname $<))/journal.rules -f "$<" > "$@"If I find anything amiss (e.g., if my balances are different than
what the bank tells me), I look at hleger areg. I may tweak
my rules or my CSVs and then I run
make clean && make and try again.
Simple, plain text accounting made simple.
And if I ever want to dig deeper, hledger’s docs have more to
teach. But for now, the balance of effort vs. reward is perfect.
while reading a blog post from Jonathan Dowland↩︎
Note, this is covered by full-fledged hledger – Investements↩︎
Also covered in full-fledged hledger – Tax returns↩︎
Luckily, I speak Leet.
– Amita Ramanujan, Numb3rs, CBS’s IRC Drama
There’s an episode of the CBS prime-time drama Numb3rs that plumbs the depths of Dr. Joel Fleischman’s1 knowledge of IRC. In one scene, Fleischman wonders, “What’s ‘leet’”?
“Leet” is writing that replaces letters with numbers, e.g.,
“Numb3rs,” where 3 stands in for e.
In short, leet is like the heavy-metal “S” you drew in middle school: Sweeeeet.
/ \
/ | \
| | |
\ \
| | |
\ | /
\ /
ASCII art version of your misspent youth.Following years of keen observation, I’ve noticed Git commit hashes are also letters and numbers.
Git commit hashes are, as Fleischman might say, prime _targets for l33tification.
What can I spell with a git commit?

With hexidecimal we can spell any word containing the set of letters
{A, B, C, D, E, F}—DEADBEEF (a classic) or
ABBABABE (for Mama Mia aficionados).
This is because hexidecimal is a base-16 numbering system—a single “digit” represents 16 numbers:
Base-10: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 16 15
Base-16: 0 1 2 3 4 5 6 7 8 9 A B C D E FLeet expands our palette of words—using 0,
1, and 5 to represent O,
I, and S, respectively.
I created a script that scours a few word lists for valid words and phrases.
With it, I found masterpieces like DADB0D (dad bod),
BADA55 (bad ass), and 5ADBAB1E5 (sad
babies).
Manipulating commit hashes for fun and no profit
Git commit hashes are no mystery. A commit hash is the SHA-1 of a commit object.
And a commit object is the commit message with some metadata.
$ mkdir /tmp/BADA55-git && cd /tmp/BAD55-git
$ git init
Initialized empty Git repository in /tmp/BADA55-git/.git/
$ echo '# BADA55 git repo' > README.md && git add README.md && git commit -m 'Initial commit'
[main (root-commit) 68ec0dd] Initial commit
1 file changed, 1 insertion(+)
create mode 100644 README.md
$ git log --oneline
68ec0dd (HEAD -> main) Initial commitLet’s confirm we can recreate the commit hash:
$ git cat-file -p 68ec0dd > commit-msg
$ sha1sum <(cat \
<(printf "commit ") \
<(wc -c < commit-msg | tr -d '\n') \
<(printf '%b' '\0') commit-msg)
68ec0dd6dead532f18082b72beeb73bd828ee8fc /dev/fd/63Our repo’s first commit has the hash 68ec0dd. My goal
is:
- Make
68ec0ddbeBADA55. - Keep the commit message the same, visibly at least.
But I’ll need to change the commit to change the hash. To keep those
changes invisible in the output of git log, I’ll add a
\t and see what happens to the hash.
$ truncate -s -1 commit-msg # remove final newline
$ printf '\t\n' >> commit-msg # Add a tab
$ # Check the new SHA to see if it's BADA55
$ sha1sum <(cat \
<(printf "commit ") \
<(wc -c < commit-msg | tr -d '\n') \
<(printf '%b' '\0') commit-msg)
27b22ba5e1c837a34329891c15408208a944aa24 /dev/fd/63Success! I changed the SHA-1. Now to do this over-and-over until we
get to BADA55—mining for immature hashes.
Fortunately, user not-an-aardvark created a tool for
that—lucky-commit
that manipulates a commit message, adding a combination of
\t and [:space:] characters until you hit a
desired SHA-1.
Written in rust, lucky-commit computes all 256 unique
8-bit strings composed of only tabs and spaces. And then pads out
commits up to 48-bits with those strings, using worker threads to
quickly compute the SHA-12 of each commit.
It’s pretty fast:
$ time lucky_commit BADA555
real 0m0.091s
user 0m0.653s
sys 0m0.007s
$ git log --oneline
bada555 (HEAD -> main) Initial commit
$ xxd -c1 <(git cat-file -p 68ec0dd) | grep -cPo ': (20|09)'
12
$ xxd -c1 <(git cat-file -p HEAD) | grep -cPo ': (20|09)'
111Now we have an more than an initial commit. We have a
BADA555 initial commit.
All that’s left to do is to make ALL our commits BADA55
by abusing git hooks.
$ cat > .git/hooks/post-commit && chmod +x .git/hooks/post-commit
#!/usr/bin/env bash
echo 'L337-ifying!'
lucky_commit BADA55
$ echo 'A repo that is very l33t.' >> README.md && git commit -a -m 'l33t'
L337-ifying!
[main 0e00cb2] l33t
1 file changed, 1 insertion(+)
$ git log --oneline
bada552 (HEAD -> main) l33t
bada555 Initial commitAnd now I have a git repo almost as cool as the sweet “S” I drew in middle school.
This is a Northern Exposure spin off, right? I’ve only seen 1:48 of the show…↩︎
or SHA-256 for repos that have made the jump to a more secure hash function↩︎
GitHub has always been a great code host. But GitHub’s code review system was an afterthought. Even now, Pull Requests still lag behind.
Oh yeah, there’s pull requests now
– GitHub blog, Sat, 23 Feb 2008
When GitHub launched, it had no code review.
Ten years later, when Microsoft acquired GitHub for $7.5 Billion, GitHub’s Pull Request model—“GitHub flow”—had become the default way to collaborate via Git.
But the Pull Request was never designed. It emerged. Though not from careful consideration of the needs of developers or maintainers.
GitHub swallowed software by making it easy to host code. Code review was an afterthought.
First-generation Pull Requests
Git has built-in pull requests—git request-pull.
The Linux kernel has used them since
2005. But GitHub never used request-pull.
According to Linus Torvalds—Git’s creator—GitHub “decided to replace it with their own totally inferior version.”
When the Pull Request debuted in 2008 it worked like this:
- Create a fork and click “Pull Request.”
- Send a message to someone1 with a link to your fork, asking them to merge it.
But while git request-pull generated a message template
including a diff stat and changelog, GitHub hamstrung Pull Requests.
GitHub provided only a small, empty
<textarea>—Pull Requests were little more than
unstructured emails to other GitHub users.
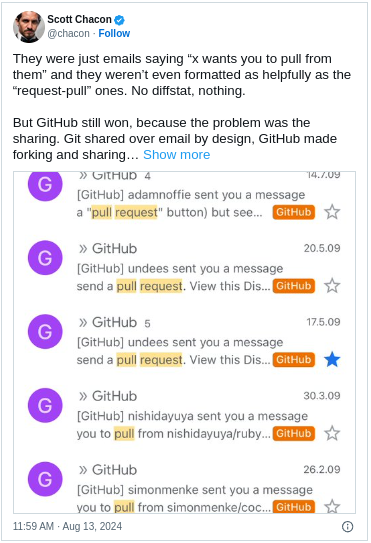
And Pull Requests still lacked any way to see changes via the web.
“Code Review = Discussion + Code”?
It took two years for GitHub to show the git diff
between two repos on GitHub.
In 2010, “cross repository compare view” coupled with an unthreaded comments section and became Pull Requests 2.02.
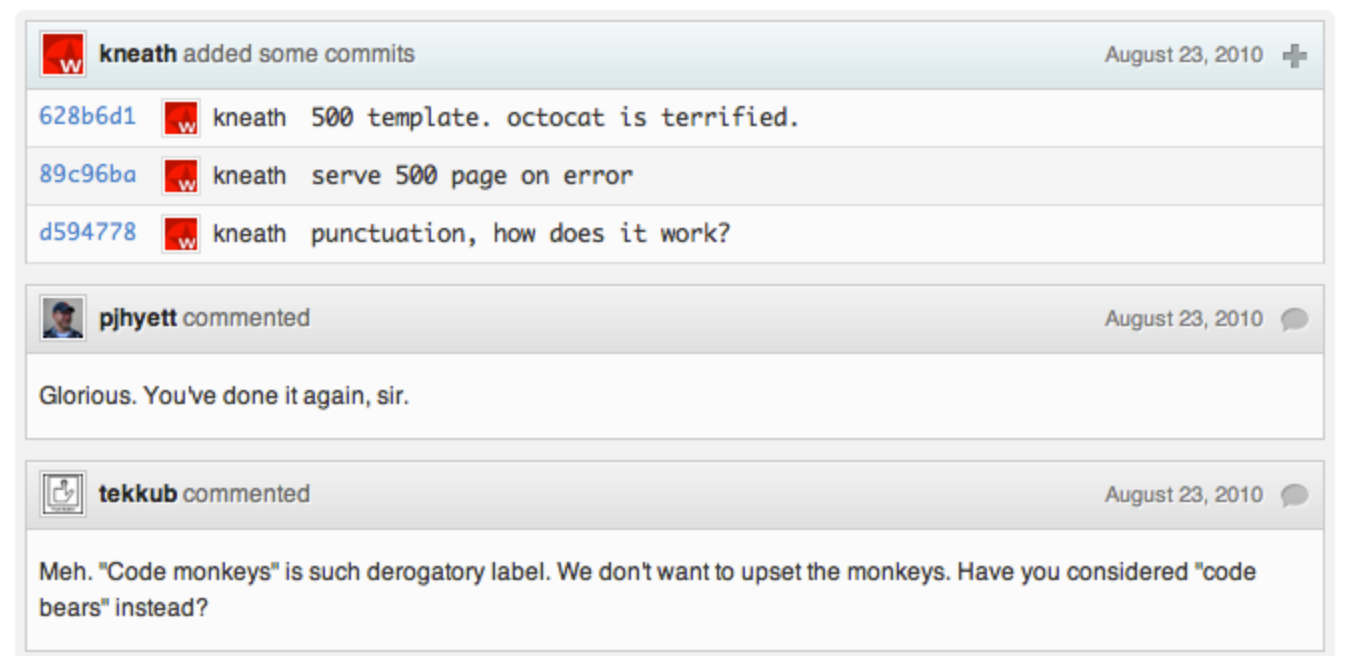
Of course, the code and the comments were still on two different pages. It took another year before you could comment in the code.
Inline code comments
In 2011, rtomayko made the first inline comment on a
change, writing, in
full: “+1”.
Inline code review was far from a revelation. Guido van Rossum’s Mondrian—his 20% project at Google—had inline code comments by 2006. And there was an open-source version of Mondrian on the public web by 2008.
The Linux Kernel (using git format-patch) had code comments since 2005.
GitHub’s code review is still behind.
In 2008, GitHub’s developers created a new kind of code review.
But key features were missing. GitHub slowly tacked on these features:
- 2010: Compare view
- 2011: Ignore whitespace changes
- 2016: “Approve”, “Request changes”, and “Start a review”
- 2017: Required review
- 2019: Multiline comments
- 2023: Merge queues
Now, it’s 2024. And here’s a biased list of what I think is still missing:
- Commit review – Ability to comment on the commit message.
- Your turn – Like Gerrit’s attention sets – Microsoft recently did a study on a system called Nudge which was a similar idea, it yielded good results, reducing review completion time 60%.
- User-defined review labels – “Approve”/“Request changes” is so limited—instead of using a complicated system of tags to mark changes ready for design approval, technical writing approval, style approval, and code approval—let repo owners figure out what approvals make sense for their project.
- Hide bot comments – Allow me to hide bot comments so I can see the human comments.
- Push to pull – Push to a special remote to create a
pull request using my commit:
git push origin <branch>:refs/pull-request/<_target-branch>. - Review in notes – Annotate commits with metadata in
a special
git
note
refs/notes/review. - Stacked diffs – Just come on. You have infinite money.
And at this point I made Gerrit, but with more branches.
“Someone” was a person chosen by you from a checklist of the people who had also forked this repository at some point.↩︎
“Code Review = Discussion + Code.” was the headline of a blog post GitHub wrote circa 2010 introducing Pull Requests 2.0↩︎
GIT - the stupid content tracker
– Linus Torvalds, Initial revision of “git”, the information manager from hell
After years of code review with stacked diffs1, I’ve been using GitLab merge requests at work.
Merge requests frustrated me until helpful folks pointed me toward GerritLab, a small Python tool for making stacked merge requests in GitLab—exactly what I was looking for.
But to talk to GitLab, GerritLab required a cleartext token in my
~/.gitconfig. I wanted to stow my token in a password
vault, so I crafted a change for GerritLab that used gitcredentials(7).
Like most git features, git credentials are obscure,
byzantine, and incredibly useful. It works like this:
import subprocess, json
INPUT = """\
protocol=https
host=example.com
username=thcipriani
"""
git_credentials_fill = subprocess.run(
["git", "credential", "fill"],
input=INPUT,
text=True,
stdout=subprocess.PIPE,
)
git_credentials = {
key: value for line in git_credentials_fill.stdout.splitlines()
if '=' in line
for key, value in [line.split('=', 1)]
}
print(json.dumps(git_credentials, indent=4))Which looks like this when you run it:
$ ./example-git-creds.py
Password for 'https://thcipriani@example.com':
{
"protocol": "https",
"host": "example.com",
"username": "thcipriani",
"password": "hunter2"
}The magic here is the shell command
git credentials fill, which:
- Accepts a protocol, username, and host on standard input.
- Delegates to a “git credential helper” (
git-credential-libsecretin my case). A credential helper is an executable that retrieves passwords from the OS or another program that provides secure storage. - My git credential helper checks for credentials matching
https://thcipriani@example.comand finds none. - Since my credential helper comes up empty, git prompts me for my password.
- Git sends
<key>=<value>\npairs to standard output for each of the keysprotocol,host,username, andpassword.
To stow the password for later, I can use
git credential approve.
subprocess.run(
["git", "credential", "approve"],
input=git_credentials_fill.stdout,
text=True
)If I do that, the next time I run the script, git finds the password without prompting:
$ ./example-git-creds.py
{
"protocol": "https",
"host": "example.com",
"username": "thcipriani",
"password": "hunter2"
}Git credential’s purpose
The problem git credentials solve is this:
- With git over ssh, you use your keys.
- With git over https, you type a password. Over and over and over.
Beleaguered git maintainers solved this dilemma with the credential storage system—git credentials.
With the right configuration, git will stop asking for your password when you push to an https remote.
Instead, git credentials retrieve and send auth info to remotes.
The maze of options
My mind initially refused to learn git credentials due to its twisty little maze of terms that all sound alike:
git credential fill: how you invoke a user’s configured git credential helpergit credential approve: how you save git credentials (if this is supported by the user’s git credential helper)git credential.helper: the git config that points to a script that poops out usernames and passwords. These helper scripts are often namedgit-credential-<something>.git-credential-cache: a specific, built-in git credential helper that caches credentials in memory for a while.git-credential-store: STOP. DON’T TOUCH. This is a specific, built-in git credential helper that stores credentials in cleartext in your home directory. Whomp whomp.git-credential-manager: a specific and confusingly named git credential helper from Microsoft®. If you’re on Linux or Mac, feel free to ignore it.
But once I mapped the terms, I only needed to pick a git credential helper.
Configuring good credential helpers
The built-in git-credential-store is a bad credential
helper—it saves your passwords in cleartext in
~/.git-credentials.2
If you’re on a Mac, you’re in luck3—one command points git credentials to your keychain:
git config --global credential.helper osxkeychainThird-party developers have contributed helpers for popular password stores:
- 1Password
- pass: the standard Unix password manager
- OAuth
- Git’s documentation contains a list of credential-helpers, too
Meanwhile, Linux and Windows have standard options. Git’s source repo includes helpers for these options in the contrib directory.
On Linux, you can use libsecret. Here’s how I configured it on Debian:
sudo apt install libsecret-1-0 libsecret-1-dev
cd /usr/share/doc/git/contrib/credential/libsecret/
sudo make
sudo mv git-credential-libsecret /usr/local/bin/
git config --global credential.helper libsecretOn Windows, you can use the confusingly named git credential manager. I have no idea how to do this, and I refuse to learn.
Now, if you clone a repo over https, you can push over https without pain4. Plus, now you have a handy password library for shell scripts:
#!/usr/bin/env bash
input="\
protocol=https
host=example.com
user=thcipriani
"
eval "$(echo "$input" | git credential fill)"
echo "The password is: $password"“stacked diffs” or “stacked pull-requests”—there’s no universal term.↩︎
git-credential-store is not a git credential helper of honor. No highly-esteemed passwords should be stored with it. This message is a warning about danger. The danger is still present, in your time, as it was in ours.↩︎
I think. I only have Linux computers to test this on, sorry
;_;↩︎Or the config option
pushInsteadOf, which is what I actually do.↩︎
Humans do no operate on hexadecimal symbols effectively […] there are exceptions.
– Dan Kaminsky
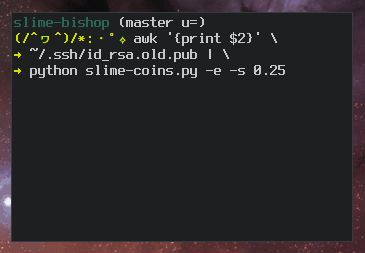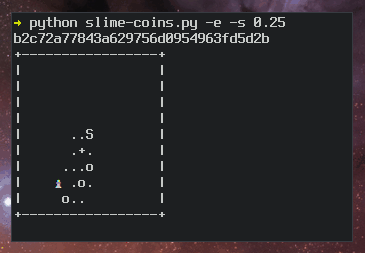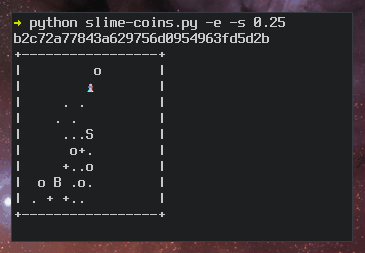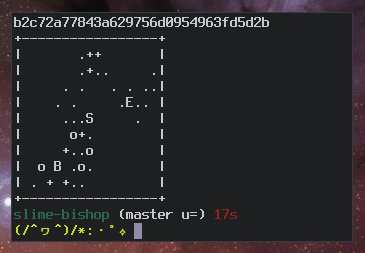
When SSH added ASCII art fingerprints (AKA, randomart), the author credited a talk by Dan Kaminsky.
As a refresher, randomart looks like this:
$ ssh-keygen -lv -f ~/.ssh/id_ed25519.pub
256 SHA256:XrvNnhQuG1ObprgdtPiqIGXUAsHT71SKh9/WAcAKoS0 thcipriani@foo.bar (ED25519)
+--[ED25519 256]--+
| .++ ... |
| o+.... o |
|E .oo=.o . |
| . .+.= . |
| o= .S.o.o |
| o o.o+.= + |
| . . .o B * |
| . . + & . |
| ..+o*.= |
+----[SHA256]-----+Ben Cox describes the algorithm for generating random art on his blog. Here’s a slo-mo version of the algorithm in action:
But in Dan’s talk, he never mentions anything about ASCII art.
Instead, his talk was about exploiting our brain’s hardware acceleration to make it easier for us to recognize SSH fingerprints.
The talk is worth watching, but I’ll attempt a summary.
What’s the problem?
We’ll never memorize
SHA256:XrvNnhQuG1ObprgdtPiqIGXUAsHT71SKh9/WAcAKoS0—hexadecimal
and base64 were built to encode large amounts of information rather than
be easy to remember.
But that’s ok for SSH keys because there are different kinds of memory:
- Rejection: I’ve never seen that before!
- Recognition: I know it’s that one—not the other one.
- Recollection: rote recall, like a phone number or address.
For SSH you’ll use recognition—do you recognize this key? Of course, SSH keys are still a problem because our working memory is too small to recognize such long strings of letters and numbers.
Hacks abound to shore up our paltry working memory—what Dan called “brain hardware acceleration.”
Randomart attempts to tap into our hardware acceleration for pattern recognition—the visiuo-spacial sketchpad, where we store pictures.
Dan’s idea tapped into a different aspect of hardware acceleration, one often cited by memory competition champions: chunking.
Memory chunking and sha256
The web service what3words maps every three cubic meters (3m²) on Earth to three words.
The White House’s Oval Office is ///curve.empty.buzz.
Three words encode the same information as latitude and
longitude—38.89, -77.03—chunking the
information to be small enough to fit in our working memory.
The mapping of locations to words uses a list of 40 thousand common English words, so each word encodes 15.29 bits of information—45.9 bits of information, identifying 64 trillion unique places.
Meanwhile sha256 is 256 bits of information: ~116 quindecillion unique combinations.
64000000000000 # 64 trillion (what3words)
115792089237316195423570985008687907853269984665640564039457584007913129639936 # 116 (ish) quindecillion (sha256)For SHA256, we need more than three words or a dictionary larger than 40,000 words.
Dan’s insight was we can identify SSH fingerprints using pairs of human names—couples.
The math works like this1:
- 131,072 first names: 17 bits per name (×2)
- 524,288 last names: 19 bits per name
- 2,048 cities: 11 bits per city
- 17+17+19+11 = 64 bits
With 64 bits per couple, you could uniquely identify 116 quindecillion items with four couples.
Turning this:
$ ssh foo.bar
The authenticity of host 'foo.bar' can't be established.
ED25519 key fingerprint is SHA256:XrvNnhQuG1ObprgdtPiqIGXUAsHT71SKh9/WAcAKoS0.
Are you sure you want to continue connecting
(yes/no/[fingerprint])?Into this2:
$ ssh foo.bar
The authenticity of host 'foo.bar' can't be established.
SHA256:XrvNnhQuG1ObprgdtPiqIGXUAsHT71SKh9/WAcAKoS0
Key Data:
Svasse and Tainen Jesudasson from Fort Wayne, Indiana, United States
Illma and Sibeth Primack from Itārsi, Madhya Pradesh, India
Maarja and Nisim Balyeat from Mukilteo, Washington, United States
Hsu-Heng and Rasim Haozi from Manali, Tamil Nadu, India
Are you sure you want to continue connecting
(yes/no/[fingerprint])?With enough exposure, building recognition for these names and places should be possible—at least more possible than memorizing host keys.
I’ve modified this from the original talk, in 2006 we were using md5 fingerprints of 160-bits. Now we’re using 256-bit fingerprints, so we needed to encode even more information, but the idea still works.↩︎
A (very) rough code implementation is on my github.↩︎